
ThreadLocal的简单使用
1 | public class ThreadMain{ |
通常我们通过匿名内部类的方式定义ThreadLocal的子类,提供初始的变量值。
TestClient线程产生一组序列号,生成三个TestClient他们共享同一个TestNum实例,运行结果如下
1 | thread[Thread-0]-->sn[1] |
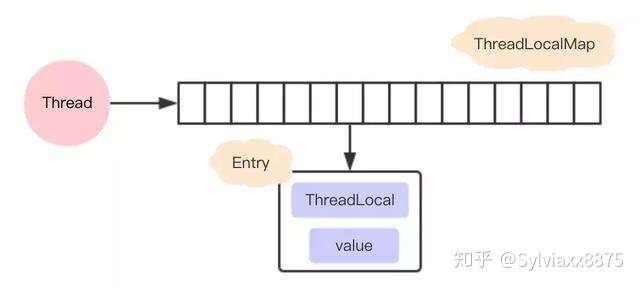
线程个隔离的秘密就在于ThreadLocalMap这个类,ThreadLocalMap是ThreadLocal类的一个静态内部类,它实现了键值对的设置和获取(对比Map对象来理解),每个线程中都有一个独立的ThreadLocalMap的副本,它所存储的值只能被当前的线程读取和修改。ThreadLocal通过操作每一个线程所独有的ThreadLocaMap的副本,从而实现了变量访问在不同线程中的隔离。
ThreadLocalMap中的键值对中的键是this对象指向的ThreadLocal对象,而值就是自己设置的对象。
源码解析重新排版
以下部分原文
ThreadLocal 是一个线程的本地变量,也就意味着这个变量是线程独有的,是不能与其他线程共享的,这样就可以避免资源竞争带来的多线程的问题,这种解决多线程的安全问题和lock(这里的lock 指通过synchronized 或者Lock 等实现的锁) 是有本质的区别的:
- lock 的资源是多个线程共享的,所以访问的时候需要加锁。
- ThreadLocal 是每个线程都有一个副本,是不需要加锁的。
- lock 是通过时间换空间的做法。
- ThreadLocal 是典型的通过空间换时间的做法。
当然他们的使用场景也是不同的,关键看你的资源是需要多线程之间共享的还是单线程内部共享的
使用
ThreadLocal 的使用是非常简单的,看下面的代码
1 | public class Test { |
看到这里是不是觉得特别简单?别高兴太早,点进去代码看看,你绝对会怀疑人生
源码分析
在分析源码之前先画一下ThreadLocal ,ThreadLocalMap 和Thread 的关系,如果你对他们的关系还不了解的话,请看我的另一篇文章BAT面试必考:ThreadLocal ,ThreadLocalMap 和Thread 的关系
set 方法
1 | public void set(T value) { |
createMap 方法只是在第一次设置值的时候创建一个ThreadLocalMap 赋值给Thread 对象的threadLocals 属性进行绑定,以后就可以直接通过这个属性获取到值了。从这里可以看出,为什么说ThreadLocal 是线程本地变量来的了
1 | void createMap(Thread t, T firstValue) { |
值真正是放在ThreadLocalMap 中存取的,ThreadLocalMap 内部类有一个Entry 类,key是ThreadLocal 对象,value 就是你要存放的值,上面的代码value 存放的就是hello word。ThreadLocalMap 和HashMap的功能类似,但是实现上却有很大的不同:
- HashMap 的数据结构是数组+链表
- ThreadLocalMap的数据结构仅仅是数组
- HashMap 是通过链地址法解决hash 冲突的问题
- ThreadLocalMap 是通过开放地址法来解决hash 冲突的问题
- HashMap 里面的Entry 内部类的引用都是强引用
- ThreadLocalMap里面的Entry 内部类中的key 是弱引用,value 是强引用
为什么ThreadLocalMap 采用开放地址法来解决哈希冲突?
jdk 中大多数的类都是采用了链地址法来解决hash 冲突,为什么ThreadLocalMap 采用开放地址法来解决哈希冲突呢?首先我们来看看这两种不同的方式
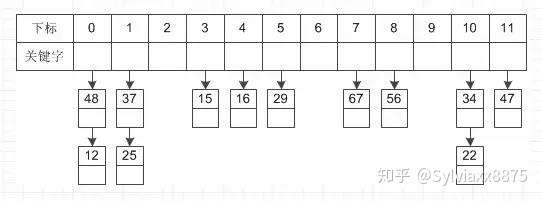
链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。列如对于关键字集合{12,67,56,16,25,37, 22,29,15,47,48,34},我们用前面同样的12为除数,进行除留余数法:
开放地址法
这种方法的基本思想是一旦发生了冲突,就去寻找下一个空的散列地址(这非常重要,源码都是根据这个特性,必须理解这里才能往下走),只要散列表足够大,空的散列地址总能找到,并将记录存入。
比如说,我们的关键字集合为{12,33,4,5,15,25},表长为10。 我们用散列函数f(key) = key mod l0。 当计算前S个数{12,33,4,5}时,都是没有冲突的散列地址,直接存入(蓝色代表为空的,可以存放数据):

计算key = 15时,发现f(15) = 5,此时就与5所在的位置冲突。于是我们应用上面的公式f(15) = (f(15)+1) mod 10 =6。于是将15存入下标为6的位置。这其实就是房子被人买了于是买下一间的作法:

链地址法和开放地址法的优缺点
开放地址法:
- 容易产生堆积问题,不适于大规模的数据存储。
- 散列函数的设计对冲突会有很大的影响,插入时可能会出现多次冲突的现象。
- 删除的元素是多个冲突元素中的一个,需要对后面的元素作处理,实现较复杂。
链地址法:
- 处理冲突简单,且无堆积现象,平均查找长度短。
- 链表中的结点是动态申请的,适合构造表不能确定长度的情况。
- 删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
- 指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间。
ThreadLocalMap 采用开放地址法原因
- ThreadLocal 中看到一个属性 HASH_INCREMENT = 0x61c88647 ,0x61c88647 是一个神奇的数字,让哈希码能均匀的分布在2的N次方的数组里, 即 Entry[] table,关于这个神奇的数字google 有很多解析,这里就不重复说了
- ThreadLocal 往往存放的数据量不会特别大(而且key 是弱引用又会被垃圾回收,及时让数据量更小),这个时候开放地址法简单的结构会显得更省空间,同时数组的查询效率也是非常高,加上第一点的保障,冲突概率也低
弱引用
接下来我们看看ThreadLocalMap 中的存放数据的内部类Entry 的实现源码
1 | static class Entry extends WeakReference<ThreadLocal<?>> { |
我们可以知道Entry 的key 是一个弱引用,也就意味这可能会被垃圾回收器回收掉threadLocal.get()==null
也就意味着被回收掉了
ThreadLocalMap set 方法
1 | private void set(ThreadLocal<?> key, Object value) { |
还是拿上面解释开放地址法解释的例子来说明下。 比如说,我们的关键字集合为{12,33,4,5,15,25},表长为10。 我们用散列函数f(key) = key mod l0。 当计算前S个数{12,33,4,5,15,25}时,并且此时key=33,k=5 已经过期了(蓝色代表为空的,可以存放数据,红色代表key 过期,过期的key为null):
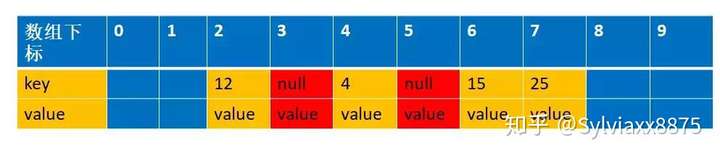
这时候来了一个新的数据,key=15,value=new,通过计算f(15)=5,此时5已经过期,进入到下面这个if 语句
1 | if (k == null) { |
replaceStaleEntry 这个方法
1 | private void replaceStaleEntry(ThreadLocal<?> key, Object value, |
第一个for 循环是向前遍历数据的,直到遍历到空的entry 就停止(这个是根据开放地址的线性探测法),这里的例子就是遍历到index=1就停止了。向前遍历的过程同时会找出过期的key,这个时候找到的是下标index=3 的为过期,进入到
1 | if (e.get() == null) |
注意此时slotToExpunge=3,staleSlot=5
第二个for 循环是从index=staleSlot开始,向后编列的,找出是否有和当前匹配的key,有的话进行清理过期的对象和重新设置当前的值。这个例子遍历到index=6 的时候,匹配到key=15的值,进入如下代码
1 | if (k == key) { |
先进行数据交换,注意此时slotToExpunge=3,staleSlot=5,i=6。这里就是把5 和6 的位置的元素进行交换,并且设置新的value=new,交换后的图是这样的
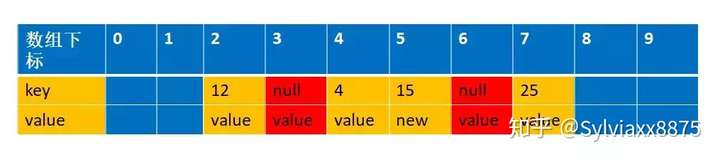
为什么要交换
这里解释下为什么交换,我们先来看看如果不交换的话,经过设置值和清理过期对象,会是以下这张图
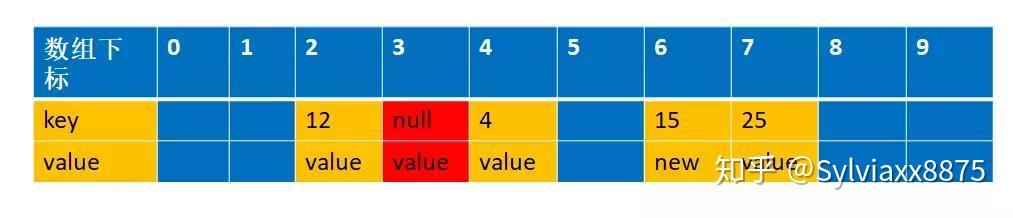
这个时候如果我们再一次设置一个key=15,value=new2 的值,通过f(15)=5,这个时候由于上次index=5是过期对象,被清空了,所以可以存在数据,那么就直接存放在这里了
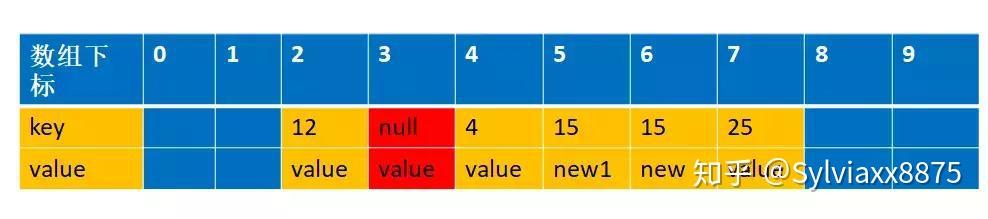
你看,这样整个数组就存在两个key=15 的数据了,这样是不允许的,所以一定要交换数据expungeStaleEntry
1 | private int expungeStaleEntry(int staleSlot) { |
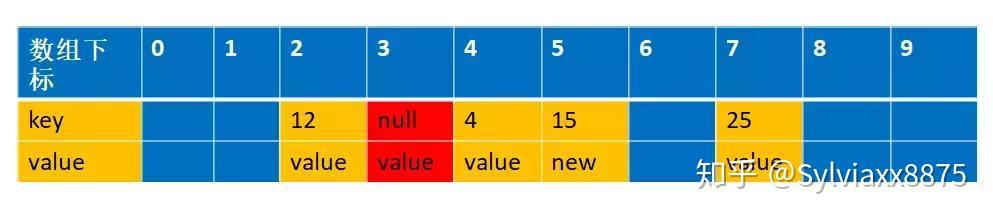
接下来我们详细模拟下整个过程 根据我们的例子,key=5,15,25 都是冲突的,并且k=5的值已经过期,经过replaceStaleEntry 方法,在进入expungeStaleEntry 方法之前,数据结构是这样的

此时传进来的参数staleSlot=6,
1 | if (k == null) { |
这个时候会把index=6设置为null,数据结构变成下面的情况
接下来我们会遍历到i=7,经过int h = k.threadLocalHashCode & (len - 1) (实际上对应我们的举例的函数int h= f(25)); 得到的h=5,而25实际存放在index=7 的位置上,这个时候我们需要从h=5的位置上重新开始编列,直到遇到空的entry 为止
1 | int h = k.threadLocalHashCode & (len - 1); |
这个时候h=6,并把k=25 的值移到index=6 的位置上,同时设置index=7 为空,如下图
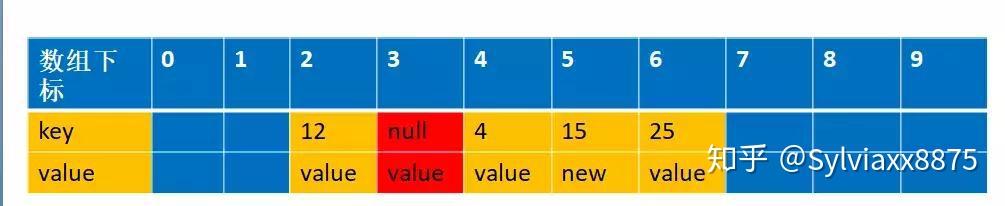
其实目的跟replaceStaleEntry 交换位置的原理是一样的,为了防止由于回收掉中间那个冲突的值,导致后面冲突的值没办法找到(因为e==null 就跳出循环了)
ThreadLocal 内存溢出问题:
通过上面的分析,我们知道expungeStaleEntry() 方法是帮助垃圾回收的,根据源码,我们可以发现 get 和set 方法都可能触发清理方法expungeStaleEntry(),所以正常情况下是不会有内存溢出的 但是如果我们没有调用get 和set 的时候就会可能面临着内存溢出,养成好习惯不再使用的时候调用remove(),加快垃圾回收,避免内存溢出
退一步说,就算我们没有调用get 和set 和remove 方法,线程结束的时候,也就没有强引用再指向ThreadLocal 中的ThreadLocalMap了,这样ThreadLocalMap 和里面的元素也会被回收掉,但是有一种危险是,如果线程是线程池的, 在线程执行完代码的时候并没有结束,只是归还给线程池,这个时候ThreadLocalMap 和里面的元素是不会回收掉的
